ФЕДЕРАЛЬНОЕ АГЕНТСТВО
ПО ТЕХНИЧЕСКОМУ РЕГУЛИРОВАНИЮ И МЕТРОЛОГИИ
|
|
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ |
ГОСТ
Р (МЭК 61164:1995) |

МЕНЕДЖМЕНТ РИСКА
ПОВЫШЕНИЕ НАДЕЖНОСТИ
СТАТИСТИЧЕСКИЕ КРИТЕРИИ И МЕТОДЫ ОЦЕНКИ
IEC
61164:1995
Reliability growth - Statistical test and estimation methods
(MOD)
![]()
Москва
Стандартинформ
2005
Предисловие
Цели и принципы стандартизации в Российской Федерации установлены Федеральным законом от 27 декабря 2002 г. № 184-ФЗ «О техническом регулировании», а правила применения национальных стандартов Российской Федерации - ГОСТ Р 1.0-2004 «Стандартизация в Российской Федерации. Основные положения»
Сведения о стандарте
1 ПОДГОТОВЛЕН Открытым акционерным обществом «Научно-исследовательский центр контроля и диагностики технических систем» (ОАО НИЦ КД) на основе собственного аутентичного перевода стандарта, указанного в пункте 4
2 ВНЕСЕН Управлением развития, информационного обеспечения и аккредитации Федерального агентства по техническому регулированию и метрологии
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 30 сентября 2005 г. № 235-ст
4 Настоящий стандарт является модифицированным по отношению к международному стандарту МЭК 61164:1995 «Повышение надежности. Статистические критерии и методы оценки» (IEC 61164:1995 «Reliability growth - Statistical test and estimation methods») для выполнения правовых или нормативно-правовых требований, установленных в Российской Федерации, путем внесения технических отклонений, объяснение которых дано во введении к настоящему стандарту.
Наименование настоящего стандарта изменено относительно наименования указанного международного стандарта для приведения в соответствие с ГОСТ Р 1.5-2004 (подраздел 3.5)
5 ВВЕДЕН ВПЕРВЫЕ
Информация об изменениях к настоящему стандарту публикуется в ежегодно издаваемом информационном указателе «Национальные стандарты», а текст изменений и поправок - в ежемесячно издаваемых информационных указателях «Национальные стандарты». В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ежемесячно издаваемом информационном указателе «Национальные стандарты». Соответствующая информация, уведомление и тексты размещаются также в информационной системе общего пользования - на официальном сайте национального органа Российской Федерации по стандартизации в сети Интернет
СОДЕРЖАНИЕ
Введение
Настоящий стандарт относится к комплексу стандартов, распространяющихся на менеджмент риска, и в части методов анализа риска развивает и дополняет ГОСТ Р 51901-2002 «Управление надежностью. Анализ риска технологических систем». Приведенные в стандарте методы могут быть применены для оценки вероятностных характеристик технических систем (далее - система) на этапе анализа и оценки риска. Стандарт описывает степенную модель повышения надежности и соответствующую модель прогнозирования и дает поэтапное руководство для их использования. Существует несколько моделей повышения надежности, однако степенная модель является одной из наиболее широко используемых. Настоящий стандарт устанавливает процедуры оценки некоторых или всех характеристик повышения надежности. Приведенные в стандарте методы в качестве исходных данных используют наработки до отказов системы и время завершения испытаний, если оно не совпадает со временем последнего отказа. Предполагается, что сбор исходных данных для построения модели начинается после завершения всех предварительных тестов по стабилизации начальной интенсивности отказов системы.
В отличие от применяемого международного стандарта в настоящий стандарт не включены ссылки на МЭК 60050 (191):1990 «Международный электротехнический словарь. Глава 191. Надежность и качество обслуживания», МЭК 60605-1:1978 «Испытания на надежность оборудования. Часть 1. Общие требования», МЭК 60605-4:1986 «Испытания на надежность оборудования. Часть 4. Процедуры определения точечных оценок и доверительных границ по результатам определительных испытаний на надежность» и МЭК 60605-6:1986 «Испытания на надежность оборудования. Часть 6. Тесты для проверки предположения о постоянстве интенсивности отказов», которые нецелесообразно использовать в национальном стандарте из-за отсутствия принятых гармонизированных национальных стандартов. В соответствии с этим изменено содержание разделов 3 и 7.
ГОСТ Р 51901.16-2005
(МЭК 61164:1995)
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Менеджмент риска
ПОВЫШЕНИЕ НАДЕЖНОСТИ
Статистические критерии и методы оценки
Risk management. Reliability growth. Statistical test and estimation methods
Дата введения - 2006-01-01
1 Область применения
Настоящий стандарт описывает модели и количественные методы оценки повышения надежности, основанные на данных об отказах системы, полученных в соответствии с программой повышения надежности. Эти процедуры позволяют определять точечные оценки, доверительные интервалы и проверять гипотезы для характеристик повышения надежности системы.
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующий стандарт:
ГОСТ Р 51901.6-2005 (МЭК 61014:2003) Менеджмент риска. Программы повышения надежности (МЭК 61014:2003 «Программы повышения надежности», MOD)
Примечание - При пользовании настоящим стандартом целесообразно проверить действие ссылочного стандарта в информационной системе общего пользования - на официальном сайте национального органа Российской Федерации по стандартизации в сети Интернет или по ежегодно издаваемому информационному указателю «Национальные стандарты», который опубликован по состоянию на 1 января текущего года, и по соответствующим ежемесячно издаваемым информационным указателям, опубликованным в текущем году. Если ссылочный стандарт заменен (изменен), то при пользовании настоящим стандартом следует руководствоваться замененным (измененным) стандартом. Если ссылочный стандарт отменен без замены, то положение, в котором дана ссылка на него, применяется в части, не затрагивающей эту ссылку.
3 Термины и определения
В настоящем стандарте применены термины по ГОСТ Р 51901.6, а также следующие термины с соответствующими определениями:
3.1 отсроченная модификация (delayed modification): Корректирующие изменения, которые введены в систему после окончания испытаний.
Примечание - Отсроченную модификацию не проводят в процессе испытаний.
3.2 коэффициент эффективности улучшения (improvement effectiveness factor): Доля интенсивности отказов системы, на которую она уменьшилась в результате корректирующей модификации.
3.3 испытания типа I (type I test): Испытания, которые заканчиваются в заранее определенное время, или испытания, для которых данные об отказах могут быть получены в течение времени, не зависящего от отказов.
Примечание - Испытания типа I иногда называют испытаниями с ограниченным временем.
3.4 испытания типа II (type II test): Испытания на повышение надежности, которые заканчиваются после накопления указанного количества отказов, или испытания, данные которых могут быть получены в течение времени, заканчивающегося отказом.
Примечание - Испытания типа II иногда называют испытаниями с ограниченным количеством отказов.
4 Обозначения
В настоящем стандарте использованы следующие обозначения:
l, b - параметры масштаба и формы для степенной модели;
CV - критические значения для проверки гипотез;
d - количество интервалов для анализа сгруппированных данных;
Eh, Ej, ![]() -
индивидуальные коэффициенты эффективности улучшения и их среднее;
-
индивидуальные коэффициенты эффективности улучшения и их среднее;
J - количество различных типов наблюдаемых отказов категории В;
i, j - универсальные индексы;
КА - количество отказов категории А;
КB - количество отказов категории В;
Кi -
количество наблюдаемых отказов i-го
типа категории В; ![]()
М - параметр статистического критерия Крамера-Мизеса;
N - количество отказов;
Ni - количество отказов в i-м интервале;
N(T) - накопленное количество отказов до истечения времени испытаний Т,
E[N(T)] - математическое ожидание накопленного количества отказов до истечения времени Т,
t(i - 1); t(i) - границы i-го интервала времени испытаний для сгруппированных данных;
Т - время испытаний;
Ti - наработка до i-го отказа;
TN - общая продолжительность испытаний типа II;
Т* - общая продолжительность испытаний типа I;
![]() -
квантиль χ2-распределения с v
степенями свободы уровня g;
-
квантиль χ2-распределения с v
степенями свободы уровня g;
z - общее обозначение для параметра потока отказов;
иу - квантиль стандартного нормального распределения уровня g;
zp - прогнозируемый параметр потока отказов;
z(T) - параметр потока отказов в момент времени Т,
θ(T) - текущее значение среднего времени между отказами;
θp - прогнозируемая средняя наработка между отказами.
5 Степенная модель
В статистических процедурах для степенной модели повышения надежности в качестве исходных данных используют отказы и наработки в процессе испытаний. За исключением метода прогнозирования (см. 7.6), модель применяют к общей совокупности отказов [см. ГОСТ Р 51901.6, рисунок 2, характеристика (3)] без подразделения на категории.
Основные уравнения для степенной модели приведены в настоящем разделе, а теоретическая информация о модели приведена в приложении В.
Математическое ожидание общего количества отказов до истечения времени испытаний T описывается степенной функцией:
E[N(T)] = lTb, l > 0, b > 0, T > 0, (1)
где l - параметр масштаба;
b - параметр формы (функция общей эффективности улучшения соответствует: повышению надежности, если 0 < b < 1; сохранению надежности, если b = 1; снижению надежности, если b > 1).
Параметр потока отказов в момент времени дописывается уравнением
![]() где Т > 0. (2)
где Т > 0. (2)
Таким образом, оба параметра l и b влияют на параметр потока отказов. Уравнение (2) представляет собой угол наклона касательной N(T) к оси Т в момент времени Т [см. ГОСТ Р 51901.6, рисунок 6].
Значение среднего времени между отказами по истечении времени испытаний Т описывается уравнением
![]() (3)
(3)
В 7.1 и 7.2 приведены оценки максимального правдоподобия для параметров l и b. В 7.3 приведены критерии согласия для модели, а в 7.4 и 7.5 - процедуры определения доверительного интервала. Применение модели для прогноза повышения надежности описано в 7.6.
Модель имеет следующие характерные особенности:
- модель проста для определения оценок;
- если параметры были оценены по прошлым программам, это - удобный инструмент для планирования будущих программ, использующих аналогичные условия испытаний и такие же коэффициенты эффективности улучшения (см. раздел 5 и ГОСТ Р 51901.6, раздел 6);
- иногда модель дает нереальные значения [например, z(Т) = ∞ в момент времени Т = 0, z(Т) стремится к нулю при Т, стремящемся к бесконечности], однако эти ограничения не влияют на практическое использование модели;
- модель является относительно инертной и нечувствительной к увеличению надежности сразу после корректирующей модификации и может давать заниженную (пессимистическую) оценку θ(T), если только не используется для прогнозирования (см. 7.6);
- обычный метод оценки предполагает, что известно точное значение наблюдаемых наработок, но возможен альтернативный подход, когда отказы сгруппированы в пределах известного интервала времени (см. 7.2.2).
6 Использование модели для планирования программ улучшения надежности
В качестве исходных данных для процедур, описанных в 6.3 ГОСТ Р 51901.6, используют две величины, определяемые с помощью моделей повышения надежности:
- общее время испытаний в часах, необходимое для выполнения целей программы;
- математическое ожидание количества отказов за это время (общее время испытаний в часах, необходимое для выполнения целей программы).
Время испытаний затем должно быть преобразовано в календарное время с запланированным временем испытаний в неделю или месяц с учетом ожидаемого полного времени простоя (см. ниже) и других непредвиденных обстоятельств, а количество отказов увеличено с учетом появления посторонних отказов и прогноза полного времени простоя.
В качестве исходных данных могут быть использованы параметры модели, оцененные по предыдущим программам, отобранные с учетом будущего применения для испытаний подобных элементов, испытательной среды, процедур управления и других существенных факторов.
7 Статистические методы оценки и проверки гипотез
В процедурах по 7.2 используют данные об отказах системы в процессе программы испытаний для оценки повышения надежности и оценки надежности системы в конце испытаний. Оцениваемое повышение надежности является результатом корректирующих модификаций, введенных в систему в процессе испытаний. Процедуры, рассматриваемые в 7.2.1, предполагают, что наработка для каждого отказа известна. В 7.2.2 рассмотрена ситуация, когда фактическое время отказа неизвестно, а отказы сгруппированы в интервалы времени.
Для испытаний типа I с ограниченным временем Т* и испытаний типа II с ограниченным количеством отказов TN используют разные формулы (см. 7.2.1).
После процедур, описанных в 7.2.1 и 7.2.2, должны быть применены соответствующие критерии согласия (см. 7.3).
В 7.6 рассмотрена ситуация, когда корректирующие модификации введены в систему после окончания испытаний как отсроченные модификации. Метод прогнозирования позволяет оценить надежность системы после этих корректирующих модификаций.
7.2 Проверка гипотез о повышении надежности и оценка параметров
7.2.1 Случай 1 - известны наработки для каждого отказа
Метод применяют только в том случае, если наработку регистрируют для каждого отказа.
Шаг 1: Исключают посторонние отказы (см. 7.1 ГОСТ Р 51901.6 и/или другие соответствующие методы).
Шаг 2: Составляют набор данных о наработках. Для испытаний типа II необходимо также учитывать время завершения испытаний.
Шаг 3: Вычисляют тестовую статистику U:
 для
испытаний типа I; (4)
для
испытаний типа I; (4)
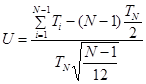 для
испытаний типа II, (5)
для
испытаний типа II, (5)
где N - общее количество отказов;
Т* - общая продолжительность испытаний типа I;
TN - общая продолжительность испытаний типа II;
Ti - наработка до i-го отказа.
В соответствии с гипотезой о постоянстве надежности (моменты отказов соответствуют гомогенному процессу Пуассона), статистика U подчиняется стандартному нормальному распределению со средним 0 и стандартным отклонением 1. Статистика U может быть использована для проверки гипотезы о наличии положительного или отрицательного изменения надежности независимо от модели повышения надежности.
Двусторонний критерий для положительного или отрицательного изменения с уровнем значимости a имеет критические значения u1-a/2 и (-u1-a/2), где u1-a/2 - квантиль стандартного нормального распределения уровня (1 - a/2).
Если U < (-u1-a/2) или U > u1-a/2, то принимают решение о положительном или отрицательном изменении надежности соответственно. Для продолжения анализа переходят к шагу 4.
Если (-u1-a/2) < U < u1-a/2, то принимают решение об отсутствии положительного или отрицательного изменения надежности для уровня значимости а и анализ заканчивают. В этом случае гипотезу об экспоненциальном распределении наработок между последовательными отказами (гомогенности процесса Пуассона) принимают с уровнем значимости a. Критические значения u1-a/2 и (-u1-a/2) соответствуют одностороннему критерию для положительного или отрицательного изменения надежности с уровнем значимости a/2. Критические значения для двустороннего критерия с уровнем значимости 0,20 составляют 1,28 и (-1,28). Критическое значение 1,28 соответствует одностороннему критерию для положительного изменения с уровнем значимости 10 %. Для других уровней значимости можно выбрать критические значения по таблицам квантилей стандартного нормального распределения.
Шаг 4: Вычисляют сумму
![]() для
испытаний типа I (6)
для
испытаний типа I (6)
или
![]() для
испытаний типа II. (7)
для
испытаний типа II. (7)
Шаг 5: Вычисляют несмещенную оценку параметра b по формуле
![]() для испытаний типа I (8)
для испытаний типа I (8)
или
![]() для испытаний типа II. (9)
для испытаний типа II. (9)
Шаг 6: Вычисляют оценку параметра l, по формуле
![]() для
испытаний типа I (10)
для
испытаний типа I (10)
или
![]() для
испытаний типа II. (11)
для
испытаний типа II. (11)
Шаг
7: Вычисляют оценки параметра потока отказов ![]() и среднего времени между
отказами
и среднего времени между
отказами ![]() для
времени испытаний Т > 0 по формулам:
для
времени испытаний Т > 0 по формулам:
![]() (12)
(12)
![]() (13)
(13)
Примечания
1 ![]() и
и ![]() - оценки параметра
потока отказов и средней наработки на отказ в момент времени T > 0 для T из диапазона
представленных данных. Оценки для будущего времени T в течение программы
испытаний или до ее ожидаемого завершения могут быть получены точно так же, но
пользоваться ими следует с обычными предосторожностями, связанными с
экстраполяцией. Экстраполяция не должна превышать ожидаемого времени завершения
испытаний.
- оценки параметра
потока отказов и средней наработки на отказ в момент времени T > 0 для T из диапазона
представленных данных. Оценки для будущего времени T в течение программы
испытаний или до ее ожидаемого завершения могут быть получены точно так же, но
пользоваться ими следует с обычными предосторожностями, связанными с
экстраполяцией. Экстраполяция не должна превышать ожидаемого времени завершения
испытаний.
2 Если
программа испытаний завершена, то ![]() для Т = T* или Т = TN (соответственно)
является оценкой средней наработки на отказ испытуемой системы в конце
программы испытаний.
для Т = T* или Т = TN (соответственно)
является оценкой средней наработки на отказ испытуемой системы в конце
программы испытаний.
7.2.2 Случай 2 - наработки объединены в группы
Метод предназначен для случая, когда набор данных состоит из известных интервалов времени, каждый из которых содержит известное количество отказов. Важно иметь в виду, что длины интервалов и количество отказов в интервалах не должны быть постоянными.
Время испытаний соответствует интервалу (0; Т) и разбито на d интервалов 0 < t(1) < t(2) < t(d); i-й интервал - это период времени от t(i - 1) до t(i), i = 1, 2, ..., d, t(0) = 0, t(d) = Т. Величины t(i) могут принимать любые значения от 0 до Т.
Шаг 1: Исключают посторонние отказы согласно 7.1 ГОСТ Р 51901.6 и/или другим соответствующим документам.
Шаг 2: Вводят в набор данных количества отказов Ni, зафиксированные в i-м интервале [t(i -1); t(i)], i = 1, …, d.
Общее
количество рассматриваемых отказов ![]()
Для каждого интервала произведение piN не должно быть менее пяти (при необходимости смежные интервалы объединяют), где
![]() (14)
(14)
Шаг 3: Для d интервалов (после объединения при необходимости) и соответствующих значений Ni вычисляют статистику X2:
![]() (15)
(15)
В соответствии с гипотезой нулевых изменений (когда наработки подчиняются гомогенному процессу Пуассона) статистика X2 распределена в соответствии с χ2-распределением с (d - 1) степенями свободы. Статистика X2 может быть использована для проверки наличия положительных или отрицательных изменений надежности независимо от модели изменений надежности.
Двусторонний критерий для положительного или отрицательного изменения с уровнем значимости a имеет критическое значение
![]() (16)
(16)
Если X2 ³ CV, то принимают решение о положительном или отрицательном изменении надежности. Для продолжения анализа переходят к шагу 4.
Если X2 < CV, то принимают решение об отсутствии положительных или отрицательных изменений надежности с уровнем значимости a. Анализ закончен. В этом случае гипотезу об экспоненциальном распределении времени между последовательными отказами (гомогенный процесс Пуассона) принимают с уровнем значимости a.
Критические
значения ![]() для различных уровней
значимости a и
степеней свободы (d - 1) могут быть найдены в таблицах квантилей χ2-распределения.
для различных уровней
значимости a и
степеней свободы (d - 1) могут быть найдены в таблицах квантилей χ2-распределения.
Шаг
4: Для первоначального набора данных в соответствии с шагом 2 вычисляют оценку
максимального правдоподобия для параметра формы b. Оценка максимального
правдоподобия для параметра b - это значение ![]() , которое удовлетворяет следующему
уравнению:
, которое удовлетворяет следующему
уравнению:
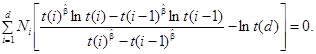 (17)
(17)
Очевидно, что t(0) = 0, а также t(0)lnt(0) = 0. Все члены t(.) могут быть нормированы относительно t(d), тогда последний член с ln(t(d)) исчезнет. Для решения этого уравнения относительно b необходимо использовать итеративный метод.
Шаг 5: Вычисляют оценку параметра l, по формуле
![]() (18)
(18)
Шаг
6: Вычисляют оценку параметра потока отказов ![]() и среднее время между
отказами
и среднее время между
отказами ![]() для
времени Т > 0 по формулам:
для
времени Т > 0 по формулам:
![]() (19)
(19)
![]() (20)
(20)
Примечания
1 ![]() и
и ![]() - оценки параметра
потока отказов и средней наработки на отказ в момент времени Т> 0 для
T из интервала представленных данных. Экстраполируемые оценки для
будущего времени T в процессе испытаний или в момент ожидаемого завершения испытаний
могут быть получены точно так же, но использовать их следует с обычными
предосторожностями, связанными с экстраполяцией. Экстраполируемые оценки не
должны выходить за границы ожидаемого времени завершения испытаний.
- оценки параметра
потока отказов и средней наработки на отказ в момент времени Т> 0 для
T из интервала представленных данных. Экстраполируемые оценки для
будущего времени T в процессе испытаний или в момент ожидаемого завершения испытаний
могут быть получены точно так же, но использовать их следует с обычными
предосторожностями, связанными с экстраполяцией. Экстраполируемые оценки не
должны выходить за границы ожидаемого времени завершения испытаний.
2 Если
программа испытаний завершена, то ![]() для Т = t(d) является оценкой
средней наработки на отказ системы на момент завершения испытаний.
для Т = t(d) является оценкой
средней наработки на отказ системы на момент завершения испытаний.
Если известны точные значения наработок, необходимо использовать случай 1, в противном случае необходимо использовать случай 2.
7.3.1 Случай 1 - известны данные о наработках для каждого отказа
Для оценки параметра формы b сначала следует использовать метод в соответствии с 7.2.1, затем вычислить статистику Крамера-Мизеса:
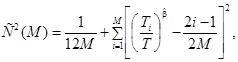 (21)
(21)
где М = N и T = Т* для испытаний типа I;
М = N - 1 и Т = TN для испытаний типа II;
Т1< Т2 < ... <TM.
В таблице 1 приведены критические значения этой статистики с уровнем значимости 10 %. Если статистика С2(М) превышает критическое значение, приведенное в таблице, то гипотеза о том, что степенная модель соответствует данным, должна быть отклонена. В противном случае гипотеза должна быть принята.
Если данные о наработках известны, для получения дополнительной информации относительно соответствия модели данным может быть использована графическая процедура, описанная ниже.
Для использования графической процедуры необходимо оценить математическое ожидание времени j-го отказа Е[Тj] и отметить на графике несоответствие с наблюдаемым временем j-го отказа Тj. В соответствии с приложением В
 j = 1, … , N. (22)
j = 1, … , N. (22)
Значения
 - изображают графически в
соответствии с наблюдаемым временем отказа Тj в
линейном масштабе (см. пример, представленный на рисунке А.1). Визуальная согласованность этих точек с линией в
45° является субъективной мерой применимости модели.
- изображают графически в
соответствии с наблюдаемым временем отказа Тj в
линейном масштабе (см. пример, представленный на рисунке А.1). Визуальная согласованность этих точек с линией в
45° является субъективной мерой применимости модели.
7.3.2 Случай 2 - наработки объединены в группы
Данный
критерий применим только в случае, когда ![]() оценивают на основе сгруппированных
данных (см. 7.2.2).
оценивают на основе сгруппированных
данных (см. 7.2.2).
Среднее количество отказов в интервале времени [t(i - 1); t(i)] аппроксимируется формулой
![]() (23)
(23)
Для каждого интервала значение ei не должно быть меньше пяти. При необходимости смежные интервалы можно объединять. Для d интервалов (после объединения при необходимости) и Ni тех же, что и в 7.2.2, вычисляют статистику:
![]() (24)
(24)
Критические значения этой статистики для (d - 2) степеней свободы можно найти по таблице χ2-распределения. Если критическое значение для уровня доверия 10 % превышено, то гипотеза о том, что степенная модель адекватно описывает сгруппированные данные, должна быть отклонена.
Если набор данных состоит из известных интервалов времени с известным количеством отказов, для получения дополнительной информации о соответствии модели данным может быть использована графическая процедура, описанная ниже.
Для каждого интервала, ограниченного точкой t(i) (от 0 до t(i)), количество наблюдаемых отказов составляет
![]() (25)
(25)
Тематическое ожидание количества отказов E[N(t(i))] оценивают по формуле
![]() (26)
(26)
Это
дает ![]()
Графическая процедура состоит из построения графика
![]() (27)
(27)
а также линии ![]() T > 0 (см. пример, изображенный на рисунке А.2). Общая информация по математическому описанию
степенной модели приведена в приложении В.
T > 0 (см. пример, изображенный на рисунке А.2). Общая информация по математическому описанию
степенной модели приведена в приложении В.
Для ![]() эта линия
убывает. Визуальная согласованность точек с этой линией является субъективной
мерой применимости модели.
эта линия
убывает. Визуальная согласованность точек с этой линией является субъективной
мерой применимости модели.
Общая информация по математическому описанию степенной модели приведена в приложении В.
7.4 Доверительные интервалы для параметра формы
Параметр формы b в степенной модели повышения надежности характеризует наличие изменений надежности и их величину. Если 0 < b < 1, имеется повышение надежности, если b = 1, нет повышения надежности, а если b > 1, имеется снижение надежности.
При определении доверительного интервала для b, когда известны наработки каждого отказа, используют случай 1. Для сгруппированных отказов необходимо использовать случай 2.
7.4.1 Случай 1 - известны наработки для каждого отказа
Шаг 1: Вычисляют b в соответствии с шагом 5 в 7.2.1.
Шаг 2: Испытания типа I.
Для определения двустороннего доверительного интервала для b с уровнем доверия 90 % вычисляют величины DL и DU.
![]() (28)
(28)
![]() (29)
(29)
Квантили
![]() ,
, ![]() определяют по таблицам
χ2-распределения.
определяют по таблицам
χ2-распределения.
Нижняя доверительная граница для b:
![]() (30)
(30)
Верхняя доверительная граница для b:
![]() (31)
(31)
Соответственно bLB и bUB являются односторонними нижней и верхней доверительными границами для b с уровнем доверия 95 %.
Испытания типа II.
Для определения двустороннего доверительного интервала для b с уровнем доверия 90 % вычисляют величины DL и DU:
![]() (32)
(32)
![]() (33)
(33)
Нижняя доверительная граница для b:
![]() (34)
(34)
Верхняя доверительная граница для b:
![]() (35)
(35)
Соответственно bLB и bUB являются односторонними нижней и верхней доверительными границами для b с уровнем доверия 95 %.
7.4.2 Случай 2 - наработки объединены в группы
Приведенные
процедуры определения границ доверительного интервала применимы в тех случаях,
когда оценка ![]() была определена по сгруппированным
данным (см. 7.2.2).
была определена по сгруппированным
данным (см. 7.2.2).
Шаг 1: Вычисляют b в соответствии с 7.2.2, шаг 4.
Шаг 2: Вычисляют значения величин P(i) (i = 1, 2, … d):
![]() i = 1, 2,
..., d. (36)
i = 1, 2,
..., d. (36)
Шаг 3: Вычисляют значение величины А:
 (37)
(37)
Шаг 4: Вычисляют значение величины С:
![]() (38)
(38)
Шаг 5: Для определения приближенного двустороннего доверительного интервала для b с уровнем доверия 90 % вычисляют
![]() (39)
(39)
где N - общее количество отказов.
Шаг 6: Нижняя доверительная граница для b:
![]() (40)
(40)
Верхняя доверительная граница для b:
![]() (41)
(41)
Соответственно bLB и bUB являются односторонними нижней и верхней доверительными границами для b с уровнем доверия 95 %.
7.5 Доверительные интервалы для средней наработки на отказ
В
соответствии с 7.2.1, шаг 7 ![]() является
оценкой θ(Т) (средняя наработка на отказ). Для доверительных
интервалов θ(Т), когда известны наработки каждого отказа,
используют случай 1. Для сгруппированных отказов используют случай 2.
является
оценкой θ(Т) (средняя наработка на отказ). Для доверительных
интервалов θ(Т), когда известны наработки каждого отказа,
используют случай 1. Для сгруппированных отказов используют случай 2.
7.5.1 Случай 1 - известны наработки для каждого отказа
Шаг
1: Вычисляют ![]() в
соответствии с 7.2.1, шаг 7.
в
соответствии с 7.2.1, шаг 7.
Шаг 2: Для определения двустороннего доверительного интервала с уровнем доверия 90 % находят значения L и U для соответствующего объема выборки N, используя таблицу 2 для испытаний типа I или таблицу 3 для испытаний типа II.
Шаг 3: Нижняя доверительная граница для θ(Т):
![]() (42)
(42)
Верхняя доверительная граница для θ(Т):
![]() (43)
(43)
Соответственно θLB и θUB являются односторонними нижней и верхней доверительными границами для θ(Т) с уровнем доверия 95 %.
7.5.2 Случай 2 - известны сгруппированные данные
Приведенные процедуры определения доверительного интервала применимы, когда оценка b была оценена по сгруппированным данным (см. 7.2.2).
Шаг
1: Вычисляют ![]() в соответствии с 7.2.2 и
в соответствии с 7.2.2 и ![]() в соответствии с 7.2.1, шаг 7.
в соответствии с 7.2.1, шаг 7.
Шаг 2: Вычисляют значения величин P(i) (i = 1, 2, ... d):
![]() i =
1, 2, … , d. (44)
i =
1, 2, … , d. (44)
Шаг 3: Вычисляют значение величины А:
(45)
Шаг 4: Вычисляют значение величины D:
![]() (46)
(46)
Шаг 5: Для приближенного определения границ двустороннего доверительного интервала для θ(Т) с уровнем доверия 90 % вычисляют значение величины S:
![]() (47)
(47)
где N - общее количество отказов.
Шаг 6: Нижняя доверительная граница для θ(Т):
![]() (48)
(48)
Верхняя доверительная граница для θ(Т):
![]() (49)
(49)
Соответственно θLB и θUB являются односторонними нижней и верхней доверительными границами для θ(Т) с уровнем доверия 95 %.
Методику применяют в тех случаях, когда корректирующие модификации включают в систему после окончания испытаний как отсроченные модификации. Цель задачи состоит в том, чтобы оценить надежность системы после введения корректирующих модификаций.
Шаг 1: Выделяют отказы категории А и категории В (см. ГОСТ 51901.6, определения 3.10 и 3.11).
Шаг 2: Идентифицируют время первого появления каждого типа отказов в категории В как отдельный набор данных. Определяют J - количество различных типов отказов категории В.
Шаг 3: Выполняют шаги от 1 до 5 в соответствии с 7.2.1 для этого набора данных и оценивают b, используя N = 1 и T* или TN для полного набора данных.
Шаг 4: Назначают каждому из J отказов различных типов категории B в наборе данных шага 2 коэффициент эффективности улучшения Ei, i = 1, ... , J. Для каждого из J отказов различных типов категории В Ei (0 £ Ei £ 1) является инженерной оценкой ожидаемого уменьшения интенсивности отказов, вызванного идентифицированной корректирующей модификацией (см. определение 3.1).
Вычисляют
среднее ![]() этих
значений. Если оно приемлемо, устанавливают средний коэффициент эффективности
улучшения (например, 0,7) вместо индивидуальных назначений Ei, i =
1, ... , J, как описано выше.
этих
значений. Если оно приемлемо, устанавливают средний коэффициент эффективности
улучшения (например, 0,7) вместо индивидуальных назначений Ei, i =
1, ... , J, как описано выше.
Шаг 5: Оценивают прогнозируемый параметр потока отказов и среднюю наработку на отказ:
![]() (50)
(50)
где КА - количество отказов категории А;
Кi - количество наблюдаемых отказов i-го типа категории В.
Т равно T* или TN, в соответствии с шагом 3.
Если
значения Еi не назначены, а есть только среднее ![]() , то средний член в квадратных
скобках становится равным
, то средний член в квадратных
скобках становится равным
![]()
где КB - количество отказов категории В
В этом случае прогнозируемый параметр потока отказов
![]() (51)
(51)
Прогнозируемое значение средней наработки на отказ θp = 1/zp.
Таблица 1 - Критические значения для критерия Крамера-Мизеса с уровнем значимости 10 %
|
Критическое значение |
М |
Критическое значение |
|
|
3 |
0,154 |
13 |
0,169 |
|
4 |
0,155 |
14 |
0,169 |
|
5 |
0,160 |
15 |
0,169 |
|
6 |
0,162 |
16 |
0,171 |
|
7 |
0,165 |
17 |
0,171 |
|
8 |
0,165 |
18 |
0,171 |
|
9 |
0,167 |
19 |
0,171 |
|
10 |
0,167 |
20 |
0,172 |
|
11 |
0,169 |
30 |
0,172 |
|
12 |
0,169 |
60 |
0,173 |
|
Примечание - Для испытаний типа I: M= N; для испытаний типа II: М = N - 1. |
|||
Таблица 2 - Двусторонние доверительные интервалы уровня доверия 90 % для средней наработки на отказ и испытаний типа I
|
L |
U |
N |
L |
U |
|
|
3 |
0,175 |
6,490 |
21 |
0,570 |
1,738 |
|
4 |
0,234 |
4,460 |
22 |
0,578 |
1,714 |
|
5 |
0,281 |
3,613 |
23 |
0,586 |
1,692 |
|
6 |
0,320 |
3,136 |
24 |
0,593 |
1,672 |
|
7 |
0,353 |
2,826 |
25 |
0,600 |
1,653 |
|
8 |
0,381 |
2,608 |
26 |
0,606 |
1,635 |
|
9 |
0,406 |
2,444 |
27 |
0,612 |
1,619 |
|
10 |
0,428 |
2,317 |
28 |
0,618 |
1,604 |
|
11 |
0,447 |
2,214 |
29 |
0,623 |
1,590 |
|
12 |
0,464 |
2,130 |
30 |
0,629 |
1,576 |
|
13 |
0,480 |
2,060 |
35 |
0,652 |
1,520 |
|
14 |
0,494 |
1,999 |
40 |
0,672 |
1,477 |
|
15 |
0,508 |
1,947 |
45 |
0,689 |
1,443 |
|
16 |
0,521 |
1,902 |
50 |
0,703 |
1,414 |
|
17 |
0,531 |
1,861 |
60 |
0,726 |
1,369 |
|
18 |
0,543 |
1,825 |
70 |
0,745 |
1,336 |
|
19 |
0,552 |
1,793 |
80 |
0,759 |
1,311 |
|
20 |
0,561 |
1,765 |
100 |
0,783 |
1,273 |
|
Примечание - Для N > 100
где |
|||||
Таблица 3 - Двусторонние доверительные интервалы уровня доверия 90 % для средней наработки на отказ и испытаний типа II
|
L |
U |
N |
L |
U |
|
|
3 |
0,1712 |
4,746 |
21 |
0,6018 |
1,701 |
|
4 |
0,2587 |
3,825 |
22 |
0,6091 |
1,680 |
|
5 |
0,3174 |
3,254 |
23 |
0,6160 |
1,659 |
|
6 |
0,3614 |
2,892 |
24 |
0,6225 |
1,790 |
|
7 |
0,3962 |
2,644 |
25 |
0,6286 |
1,623 |
|
8 |
0,4251 |
2,463 |
26 |
0,6344 |
1,608 |
|
9 |
0,4495 |
2,324 |
27 |
0,6400 |
1,592 |
|
10 |
0,4706 |
2,216 |
28 |
0,4520 |
1,578 |
|
11 |
0,4891 |
2,127 |
29 |
0,6503 |
1,566 |
|
12 |
0,5055 |
2,053 |
30 |
0,6551 |
1,553 |
|
13 |
0,5203 |
1,991 |
35 |
0,6763 |
1,501 |
|
14 |
0,5337 |
1,937 |
40 |
0,6937 |
1,461 |
|
15 |
0,5459 |
1,891 |
45 |
0,7085 |
1,428 |
|
16 |
0,5571 |
1,876 |
50 |
0,7212 |
1,401 |
|
17 |
0,5674 |
1,814 |
60 |
0,7422 |
1,360 |
|
18 |
0,5769 |
1,781 |
70 |
0,7587 |
1,327 |
|
19 |
0,5857 |
1,752 |
80 |
0,7723 |
1,303 |
|
20 |
0,5940 |
1,726 |
100 |
0,7938 |
1,267 |
|
Примечание - Для N > 100
где |
|||||
Приложение А
(справочное)
Числовые примеры
А.1 Введение
Следующие числовые примеры демонстрируют использование процедур, описанных в разделе 7. В таблице А.1 приведен полный набор данных, иллюстрирующих методы, когда известны наработки, а в таблице А.2 - для сгруппированных данных. В таблицах А.3 и А.4 приведены данные для методики прогнозирования, когда корректирующие модификации отнесены к концу испытаний. При необходимости в соответствии с 7.3 применяют критерии согласия. Эти примеры могут быть использованы для контроля соответствующих компьютерных программ, разработанных для реализации методов раздела 7.
А.2 Определение оценок показателей надежности
Набор данных в таблице А.1 соответствует испытаниям, заканчивающимся через 1000 ч. Эти данные использованы в примерах А.2.1 и А.2.2 для испытаний типа I и типа II. В сгруппированном виде эти данные представлены в таблице А.2 для примера А.2.3.
А.2.1 Пример 1 - испытания типа I - Случай 1 - известны наработки для каждого отказа
Этот случай рассмотрен в 7.2.1. Данные таблицы А.1 соответствуют испытаниям, заканчивающимся через 1000 ч.
a) Проверка гипотез на повышение надежности
U = -3,713. Критические значения для двустороннего критерия с уровнем значимости 0,20 составляют 1,28 и -1,28. Поскольку U < -1,28, имеется доказательство повышения надежности и анализ продолжается.
b) Оценка параметров
Оценки параметров степенной модели
![]() = 1,0694;
= 1,0694;
![]() = 0,5623.
= 0,5623.
c) Оценка средней наработки на отказ
Оценка средней наработки на отказ за 1000 ч составила 34,2 ч.
d) Критерий согласия
С2(М) = 0,038 с М = 52. Для уровня значимости 10 % критическое значение в соответствии с таблицей 1 составляет 0,173. Поскольку С2(М) < 0,173, степенная модель принимается (см. 7.3 и рисунок А.1).
e) Доверительный интервал для b
Двусторонний доверительный интервал для b с доверительной вероятностью 0,9 имеет вид: (0,4491; 0,7101).
f) Доверительный интервал для средней наработки на отказ
Двусторонний доверительный интервал для средней наработки на отказ за 1000 ч, соответствующий доверительной вероятности 0,9, имеет вид: (24,2 ч; 48,1 ч).
А.2.2 Пример 2 - испытания типа II - Случай 1 - известны наработки для каждого отказа
Этот случай описан в 7.2.1. Используются данные таблицы А.1 для испытаний, заканчивающихся через 975 ч.
a) Проверка гипотез о повышении надежности
U = -3,764. Для уровня значимости 0,2 критические значения для двустороннего критерия составляют 1,28 и -1,28. Поскольку U < -1,28, имеется доказательство повышения надежности и анализ продолжается.
b) Оценка параметров
Оценки параметров степенной модели
![]() = 1,1067;
= 1,1067;
![]() = 0,5594.
= 0,5594.
c) Оценка средней наработки на отказ
Оценка средней наработки на отказ за 975 ч составила 33,5 ч.
d) Критерий согласия
С2(M) = 0,041 с М = 51. Для уровня значимости 0,10 критическое значение в соответствии с таблицей 1 равно 0,173. Поскольку С2(M) < 0,173, степенная модель принимается (см. 7.3 и рисунок А.1).
e) Доверительный интервал для b
Двусторонний доверительный интервал для b с доверительной вероятностью 0,9 имеет вид: (0,4646; 0,7347).
f) Доверительный интервал для средней наработки на отказ
Двусторонний доверительный интервал для средней наработки на отказ, соответствующий доверительной вероятности 0,9, имеет вид: (24,3 ч; 46,7 ч).
А.2.3 Пример 3 - Случай 2 - сгруппированные данные
Этот случай описан в 7.2.2. Использованы данные таблицы А.1. В таблице А.2 приведены отказы, сгруппированные в интервалы по 200 ч. Анализ этого набора данных дает результаты, описанные ниже.
a) Проверка гипотез о повышении надежности
X2 = 595 с четырьмя степенями свободы. Для уровня значимости 0,20 критическое значение составляет 6,0. Поскольку X2 > 6,0, имеется доказательство положительного или отрицательного изменения надежности и анализ продолжается.
b) Оценка параметров
Оценки параметров степенной модели
![]() =
0,9615;
=
0,9615;
![]() = 0,5777.
= 0,5777.
c) Оценка средней наработки на отказ
Оценка средней наработки на отказ за 1000 ч составила 33,3 ч.
d) Критерий согласия
X2 = 2,175 стремя степенями свободы. Для уровня значимости 0,10 критическое значение составило 6,25. Поскольку X2 < 6,25, степенная модель принимается (см. 7.3 и рисунок А.2).
e) Доверительный интервал для b
Двусторонний доверительный интервал для b с доверительной вероятностью 0,9 имеет вид: (0,3202; 0,8351).
f) Доверительный интервал для средней наработки на отказ
Двусторонний доверительный интервал для средней наработки на отказ, соответствующий доверительной вероятности 0,9, имеет вид: (16,6 ч; 49,9 ч).
А.3 Прогнозируемые оценки показателей надежности
Данный пример иллюстрирует расчет прогнозируемых оценок показателей надежности (см. 7.6), когда корректирующие модификации введены в систему в конце испытаний.
А.3.1 Пример 4
Основные данные, используемые в примере, приведены в таблице А.3. Имеется общее количество отказов N = 45 с КА = 13 категориями отказов при отсутствии корректирующей модификации. В конце 4000 ч испытаний в систему было введено J = 16 различных корректирующих модификаций, направленных на отказы КB = 32 категории В. Категория для каждого отказа приведена в таблице А.3. В таблице А.4 представлена дополнительная информация, используемая для прогнозирования.
Шаги процедуры
Шаг 1: Идентифицируют категории отказов А и В.
Времена появления отказов категорий А и В идентифицированы в таблице А.3. Наработки для 16 различных типов отказов категории В приведены в таблице А.4, столбец 2.
Шаг 2: Идентифицируют первое появление отказов различных типов категории В.
Времена первого появления отказов для 16 различных типов категории В приведены в таблице А.4, столбец 3.
Шаг 3: Анализируют данные первого появления отказов.
Набор данных таблицы А.4, столбца 3 проанализирован в соответствии с шагами 4 - 8 из 7.2.1. Результаты приведены ниже.
Оценка параметров
Оценки параметров степенной модели
![]() =
0,0326;
=
0,0326;
![]() = 0,7472.
= 0,7472.
Оценка параметра потока первого появления отказов
Оценка интенсивности отказов различных типов категории В для первого появления за 4000 ч составила 0,0030 ч-1.
Критерии согласия
С2(M) = 0,085 с М = 16. Для уровня значимости 0,10 критическое значение в соответствии с таблицей 1 составило 0,171. Поскольку С2(M) < 0,171, степенная модель принята для времен первого появления отказов различных типов категории В.
Шаг 4: Назначают коэффициенты эффективности улучшения.
Пример назначенных индивидуальных коэффициентов эффективности улучшения для каждой корректирующей модификации приведен в таблице А.4, столбец 5. Среднее этих 16 коэффициентов эффективности составляет 0,72. Среднее в диапазоне 0,65 - 0,75 является типичным (основано на историческом опыте).
Шаг 5: Оценивают прогнозируемый параметр потока отказов.
Для вычисления прогнозируемого параметра потока отказов необходимы значения следующих величин:
Т = 4000 ч;
КА = 13;
J = 16;
![]() =
0,7472;
=
0,7472;
![]() =
0,72;
=
0,72;
Ki - таблица А.4, столбец 4;
Ei - таблица А.4, столбец 5.
Оценка прогнозируемого параметра потока отказов в момент времени Т = 4000 ч (конец испытаний) составила 0,0074 ч-1.
Шаг 6: Оценивают прогнозируемое значение средней наработки на отказ. Прогнозируемая оценка средней наработки на отказ составила 135,1 ч.
Примечание - Без повышения надежности в течение 4000 ч оценка средней наработки на отказ за этот период составила 88,9 ч (4000/45). Увеличение прогнозируемой оценки средней наработки на отказ вызвано введением 16 корректирующих модификаций с соответствующими коэффициентами эффективности. Необходимо принимать во внимание чувствительность прогнозируемого значения средней наработки на отказ к назначенным коэффициентам эффективности. Если бы было назначено среднее значение коэффициентов эффективности 0,60, прогнозируемое значение средней наработки на отказ равнялось бы 121,3 ч. Среднее значение коэффициентов эффективности 0,80 дает прогнозируемое значение средней наработки на отказ 138,1 ч.
Таблица А.1 - Полные данные - все отказы и наработки для испытаний типа I Т = 1000 ч, N = 52
|
4 |
10 |
15 |
18 |
19 |
20 |
25 |
39 |
|
|
41 |
43 |
45 |
47 |
66 |
88 |
97 |
104 |
105 |
|
120 |
196 |
217 |
219 |
257 |
260 |
281 |
283 |
289 |
|
307 |
329 |
357 |
372 |
374 |
393 |
403 |
466 |
521 |
|
556 |
571 |
621 |
628 |
642 |
684 |
732 |
735 |
754 |
|
792 |
803 |
805 |
832 |
836 |
873 |
975 |
|
|
Таблица А.2 - Сгруппированные данные таблицы А.1 для примера 3
|
Количество отказов |
Время испытаний, соответствующее правой точке интервала группы, ч |
|
|
1 |
20 |
200 |
|
2 |
13 |
400 |
|
3 |
5 |
600 |
|
4 |
8 |
800 |
|
5 |
6 |
1000 |
Таблица А.3 - Полные данные для прогнозируемых оценок примера 4 - все отказы и наработки T* = 4000 ч, N= 45, КА = 13, КB = 32, J = 16
|
Наработки и их классификация по категориям А/В (включая типы отказов категории В) Ti Категория |
||||||||
|
150 В1 |
253 В2 |
475 В3 |
540 В4 |
564 В5 |
636 А |
722 В5 |
871 А |
996 В6 |
|
1003 В7 |
1025 А |
1120 В8 |
1209 В2 |
1255 В9 |
1334 В10 |
1647 В9 |
1774 В10 |
1927 В11 |
|
2130 А |
2214 А |
2293 А |
2448 А |
2490 В12 |
2508 А |
2601 В1 |
2635 В8 |
2731 А |
|
2747 В6 |
2850 В13 |
3040 В9 |
3154 В4 |
3171 А |
3206 А |
3245 В12 |
3249 В10 |
3420 В5 |
|
3502 В3 |
3646 В10 |
3649 А |
3663 В2 |
3730 В8 |
3794 В14 |
3890 В15 |
3949 А |
3952 В16 |
Таблица А.4 - Различные типы отказов категории В из таблицы А.3
|
Время отказа, ч |
Время первого появления отказа, ч |
Количество наблюдений |
Назначенная эффективность факторов |
|
|
1 |
2 |
3 |
4 |
5 |
|
1 |
150; 260 |
150 |
2 |
0,7 |
|
2 |
253; 1209; 3663 |
253 |
3 |
0,7 |
|
3 |
475; 3502 |
475 |
2 |
0,8 |
|
4 |
540; 3154 |
540 |
2 |
0,8 |
|
5 |
564; 722; 3420 |
564 |
3 |
0,9 |
|
6 |
996; 2747 |
996 |
2 |
0,9 |
|
7 |
1003 |
1003 |
1 |
0,5 |
|
8 |
1120; 2635; 3730 |
1120 |
3 |
0,8 |
|
9 |
1255; 1647; 3040 |
1255 |
3 |
0,9 |
|
10 |
1334; 1774; 3249; 3646 |
1334 |
4 |
0,7 |
|
11 |
1927 |
1927 |
1 |
0,7 |
|
12 |
2490; 3245 |
2490 |
2 |
0,6 |
|
13 |
2850 |
2850 |
1 |
0,6 |
|
14 |
3794 |
3794 |
1 |
0,7 |
|
15 |
3890 |
3890 |
1 |
0,7 |
|
16 |
3952 |
3952 |
1 |
0,5 |
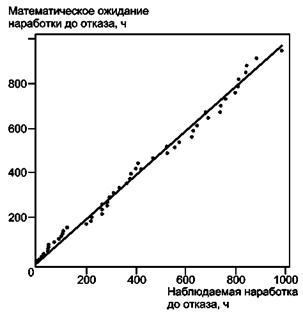
Рисунок А.1 - Диаграмма рассеяния наработок, основанная на данных таблицы А.1

Рисунок А.2 - Отношение наблюдаемого и оцененного количества отказов к наработке на основе данных таблицы А.2
Приложение В
(справочное)
Модель степенного закона повышения надежности. Общая информация
B.1 Постулат Дуайна
Наиболее часто используемая модель повышения надежности была описана Дж.Т. Дуайном в 1964 г. [1]. Дуайн анализировал данные отказов для ряда систем в процессе типовых испытаний. Он заметил, что накопленное количество отказов N(T), деленное на накопленное время испытаний Т, уменьшается и стремится к прямой линии при построении графика в логарифмическом масштабе, т.е. приблизительно,
Ln(N(T)/Т) = d - alnT, d > 0, a > 0. (В.1)
Дуайн исследовал эти графики и сделал вывод, что накопленное количество отказов аппроксимируется степенной функцией, т.е.
N(Т) = lТb, l > 0, b = 1 - a. (В.2)
Опираясь на эти наблюдения, Дуайн записал для мгновенного значения параметра потока отказов в момент времени Т:
![]() T > 0. (B.3)
T > 0. (B.3)
Тогда мгновенное значение средней наработки на отказ
![]() T
> 0. (B.4)
T
> 0. (B.4)
Показатель a = 1 - b иногда называют «интенсивностью роста».
Постулат Дуайна является детерминированным в том смысле, что он дает модель повышения надежности, но не описывает изменчивость данных.
B.2 Степенная модель
Л.Х. Кроу в 1974 г. [2] рассмотрел степенную модель изменений надежности и сформулировал основную вероятностную модель отказов как негомогенный процесс Пуассона (NHPP), {N(T), Т> 0}, со средним
Е[N(Т)] = lTb (В.5)
и функцией потока отказов
z(T) = lbTb-1. (B.6)
Модель Кроу очень похожа на модель Дуайна. Обе эти модели используют одно и то же выражение lTb для ожидаемого количества отказов в момент времени Т. Однако модель Кроу позволяет определить вероятность того, что N(T) примет конкретное значение в следующем виде:
![]() , n = 0, 1, 2, … . (B.7)
, n = 0, 1, 2, … . (B.7)
В соответствии с этой моделью
![]() j = 1, 2, ..., (В.8)
j = 1, 2, ..., (В.8)
где Tj является наработкой до j-го отказа.
Это
дает полезное первое приближение  j =
1, 2, ...
j =
1, 2, ...
для наработки до j-го отказа.
Если b = 1, то z(T) = l, и наработки между последовательными отказами подчиняются показательному распределению со средним 1/l, (гомогенный процесс Пуассона), не влияя на постоянство надежности. Функция z(Т) уменьшается для b < 1 (положительные изменения) и увеличивается для b > 1 (отрицательные изменения).
Степенная модель повышения надежности NHPP, являющаяся вероятностной интерпретацией постулата Дуайна, использует строгие статистические процедуры для метода оценки повышения надежности. Она позволяет определять оценки максимального правдоподобия и границы доверительного интервала для параметров модели и показателей надежности системы и применять критерии согласия. Степенная модель NHPP была расширена Кроу в 1983 г. [3] для прогнозирования повышения надежности.
Библиография
[1] Duane, J.T., «Learning Curve Approach to Reliability Monitoring». IEEE Transactions on Aerospace 2:1964, p. 563 - 566
Ключевые слова: менеджмент риска, анализ надежности, показатели надежности, параметр потока отказов, модель повышения надежности